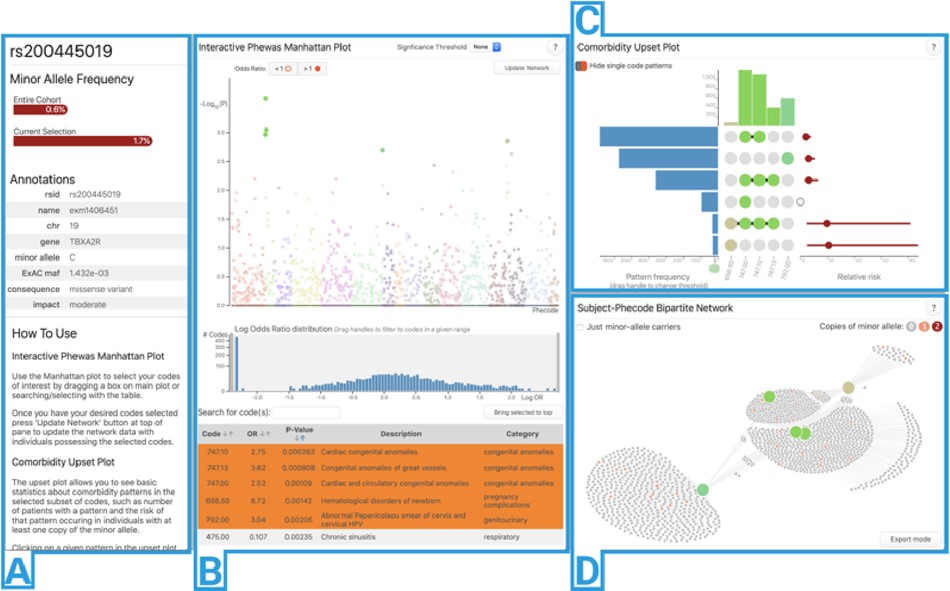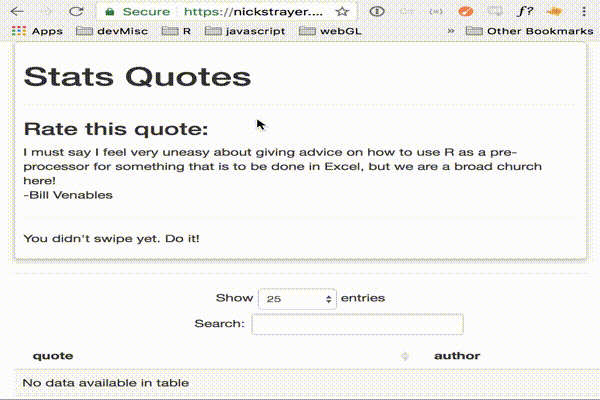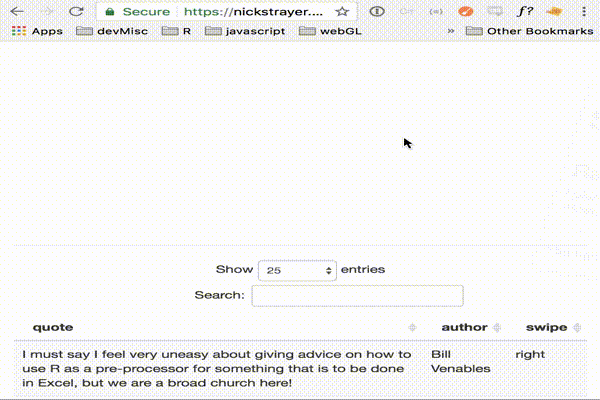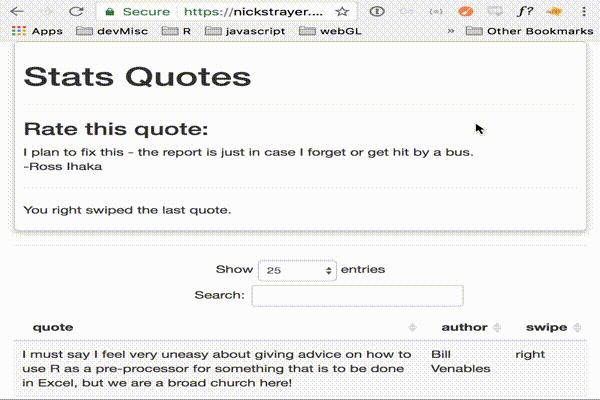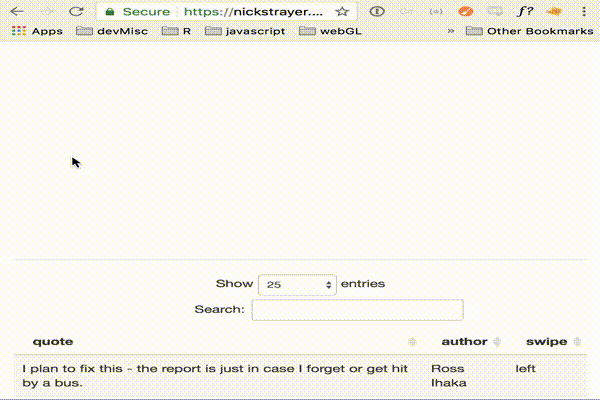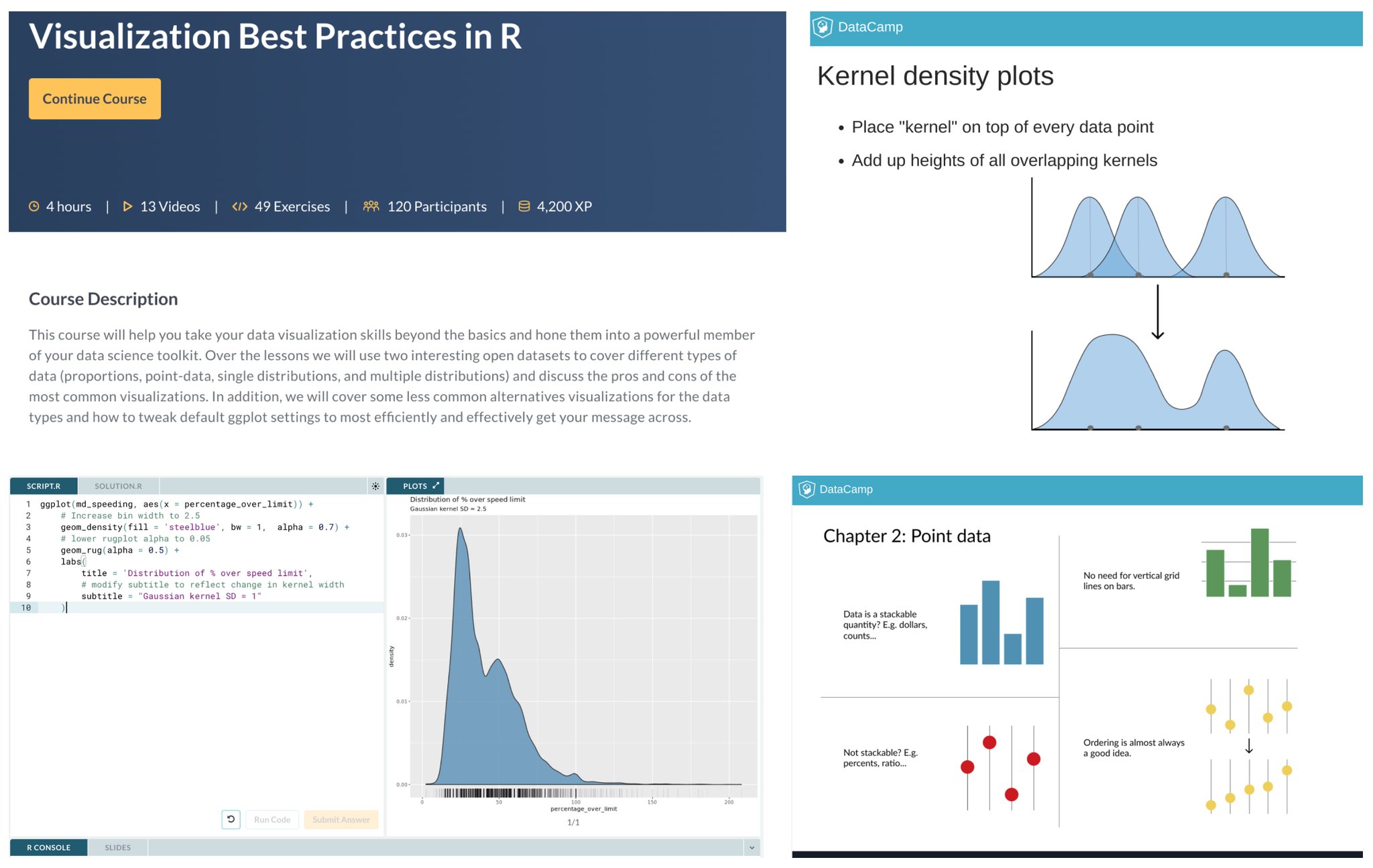
Positron IDE
A next-generation, language-agnostic data science IDE and spiritual successor to RStudio, built by Posit to unify data exploration, analysis, and production workflows
Serving as tech lead for the Jupyter notebooks experience, building a completely reimagined notebook editor from the ground up
Implementing AI-native notebook interactions that integrate intelligent assistance directly into the data analysis workflow